
Our December 10 Traffic Spike
Let’s talk about December 10, 2024 — the day our servers got their cardio workout of the year.


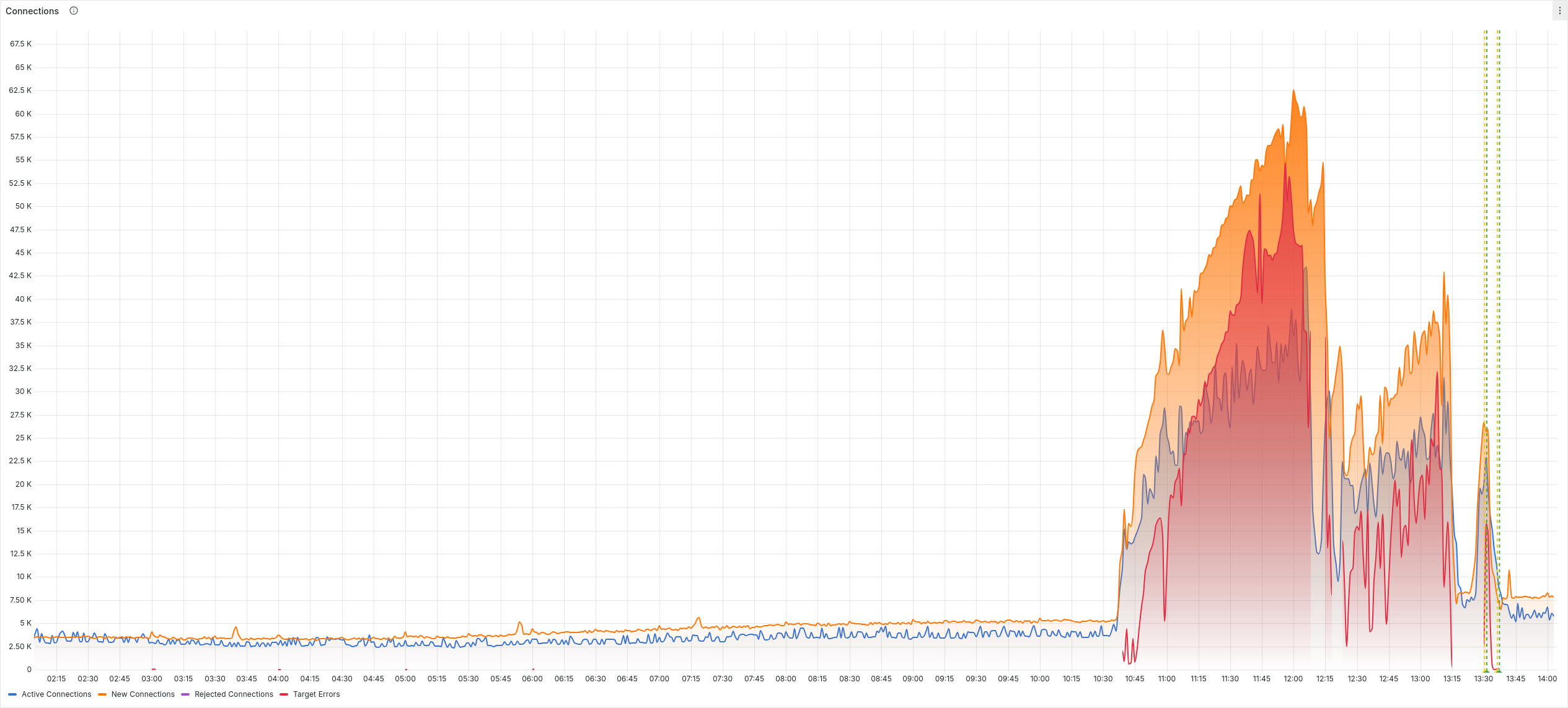
At around 10:00am UTC on December 10, 2024, we noticed something unusual: a massive spike in incoming traffic. To give you some perspective, our typical request load is around 7,000 signals per second. But for a solid 2-3 hour window, that number skyrocketed to a jaw-dropping 70,000 signals per second — a 10x increase. My phone started pinging warnings from our various monitoring systems, and I sat down and began investigating.
At first, I thought we were under a DDoS attack (paranoia is a CTO’s best friend, after all). But after diving into the data, it became clear this wasn’t a botnet gone wild. These were real, valid signals coming from real apps.
Because the spike was so large, parts of our infrastructure were not keeping up fully. The Dashboard was not reachable for an hour or two, or it was painfully slow. Our Ingest API sometimes returned "server error" or "timeout" errors.
Our DKs cache events locally, so most of the data eventually made it into our system. But I want to look deeper and be more ready if and when this happens again.
Where Did It Come From?
The surge was overwhelmingly from Android apps. Naturally, I started hunting for any big external events that could explain it. Was there a surprise Android system update? A mass reboot of phones worldwide? A viral marketing event for some app that’s suddenly on everyone’s radar?
Nope, none of those. Android 16’s developer preview did come out recently, but it’s unlikely that a preview version would cause such a surge across multiple, unrelated apps.
We’re still investigating the root cause. It’s a mystery, but that’s part of the fun, right? (That’s rhetorical. It’s not fun.)
How Did We Respond?
When something like this happens, speed matters. Here’s what we did:
- Scaled Up Our Infrastructure. Our system is built to scale, and that’s exactly what we did. We increased server capacity to keep up with demand.
- Plugged Some Holes. We found and addressed a few pressure points in our pipeline. Specifically, we discovered that our message queue parameters were configured to handle standard traffic scenarios but not a sudden 10x surge. As a result, these parameters imposed limits the number of events per second we can accept. We’ve since updated the code to allow for significantly better parallelization, ensuring that the system can scale better and remains reachable even during extreme spikes in traffic.
- Kept Our Customers Informed. We posted a status update right away to let you know what was going on and what we were doing to resolve it. We also posted updates on social media and status.telemetrydeck.com whenever we had new information.
Despite the pressure, our system managed to ingest most of the data. It wasn’t perfect, but it was solid. We’re proud of that.
What Did We Learn?
Every incident is a learning opportunity (again, not as fun as it sounds). Here's what we're implementing so we can climb the next spike more easily:
- Exponential Backoff for SDKs. Our SDKs will be updated to use exponential backoff if the ingest API becomes unreachable. This ensures apps don’t just keep slamming us with retries. It’s a more graceful way to handle downtime or congestion.
- Separate Ingestion from Processing. We’re adjusting our architecture to separate event acceptance from event processing. This means that even if processing lags behind (because, you know, 10x traffic spikes), we can still accept and queue incoming signals without dropping them.
- Decouple Query API from Ingest API. In its "health check" function, the query API sometimes sends data to the ingest API to see if it's there. Whenever the ingest API fails, the query API therefore also fails its health checks and gets rebooted, hence the slow dashboard performance. This is a spillover from years past that is no longer necessary or helpful now that we have more powerful monitoring, so we'll remove that dependency.
Looking Ahead
Incidents like this are humbling. But they’re also opportunities to prove why we’re different. Privacy-first analytics isn’t just about handling data responsibly — it’s about being honest, open, and ready to improve when things don’t go to plan.
We’re grateful for your patience and trust. If you’re curious about the technical details or just want to say hi, you know where to find us.
Until next time (hopefully under calmer conditions),
Daniel