
We've upgraded our servers
Over the last few weeks, we have completely overhauled the way we host our calculation servers. Here's what's changed and what we've learned.

Our query servers are way more efficient now! They calculate answers more quickly, and should run reliably without outages or slowdowns. They use less energy too, and the total amount of machines we use has more than halved.
This move has also eliminated a whole class of errors and breakdowns that kept popping up and interrupting the ingestion of live data.
Holy macaroni am I happy to write these lines! 🤠
We've moved hosting providers, and are mostly powered by Amazon AWS now (in Frankfurt, Germany), but our previous provider doesn't have anything to do with our bad performance.
During the move, we've overhauled our entire architecture by removing a layer of abstraction, so our query servers now run directly on virtual machines, and that's why they're faster. Bye Kubernetes, you've served us well, but you weren't the right fit for this specific workload.
Read on for a technical in-depth explanation of what's changed
Our Cloud Architecture
As you may know, the calculations behind your TelemetryDeck queries are run on Apache Druid, a flexible and efficient time-series database. Druid is highly clusterable and can be horizontally scaled.

TelemetryDeck has two main components: the Ingest API, where data is received, and the Query API, which processes database queries and returns insightful results.
Signals arrive at the Ingest API, get processed a bit and then get pushed onto a message queue, where Druid picks them up for storage.
When our customers want to see a chart, the query for that chart gets processed by the Query API, compiled to a Druid query, and then calculated on the Druid API. (Compiled because TQL has more features than the Druid Query Language, and so we expand it down to pure Druid before execution).
Druid needs serious processing power
Druid nodes need substantial RAM and CPU and that usually means one Druid Node wants to use an entire machine. But a Kubernetes-managed machine expects to run multiple small workloads, and it will also mercilessly kill these workloads when they spike above certain thresholds even for just a second.
When running on Kubernetes, we therefore had to keep away from any RAM or CPU thresholds at all costs by including very generous buffers. In practice, this meant provisioning machines with 128 gigs of RAM and then using less than half of that, just to account for very short spikes. This was inefficient, and frankly, frustrating.
It didn't even work reliably – every now and then a big request or a cluster reorganisation would knock out some containers, and because they are ephemeral, they had to reload their entire data set for a few hours before they were back in operation. This was the cause of our frequent outages in live data.
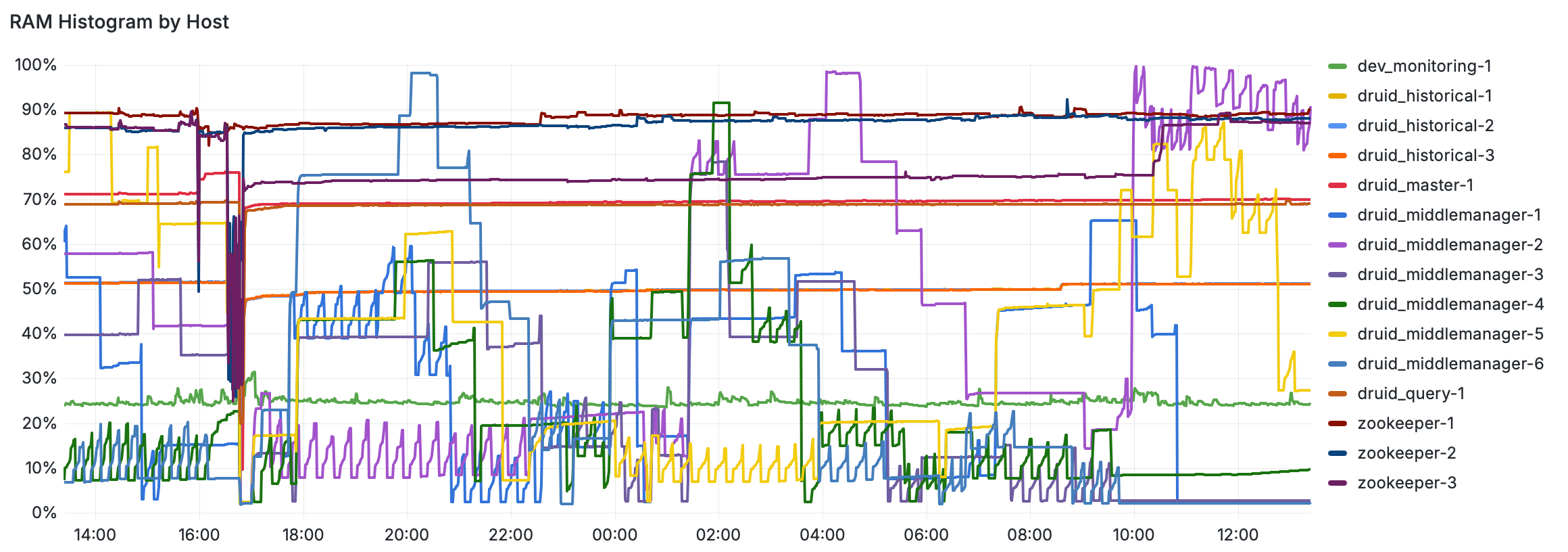
We're using virtual machines directly now
On Kubernetes, we had to leave incredibly high buffers for RAM and CPU usage. We'd tell the Druid node to use 50 gigs of RAM on a machine with 128 gigs, because one little spike would otherwise cause the Kubernetes process to kill the entire container if it ever ventured into the 100 gigs range.
Now, we target 80% RAM use and just have a lil swap space for rare spikes. That efficiency reduced our Druid cluster from around 15-20 machines on Azure down to around 8 on AWS.
Push to (cattle) prod
A wise person recently told me "Treat your servers as cattle, not pets", meaning they are replaceable and managed as a group rather than individually.
Well yee-haw, hand me my cattle prod and call me cowboy 🤠
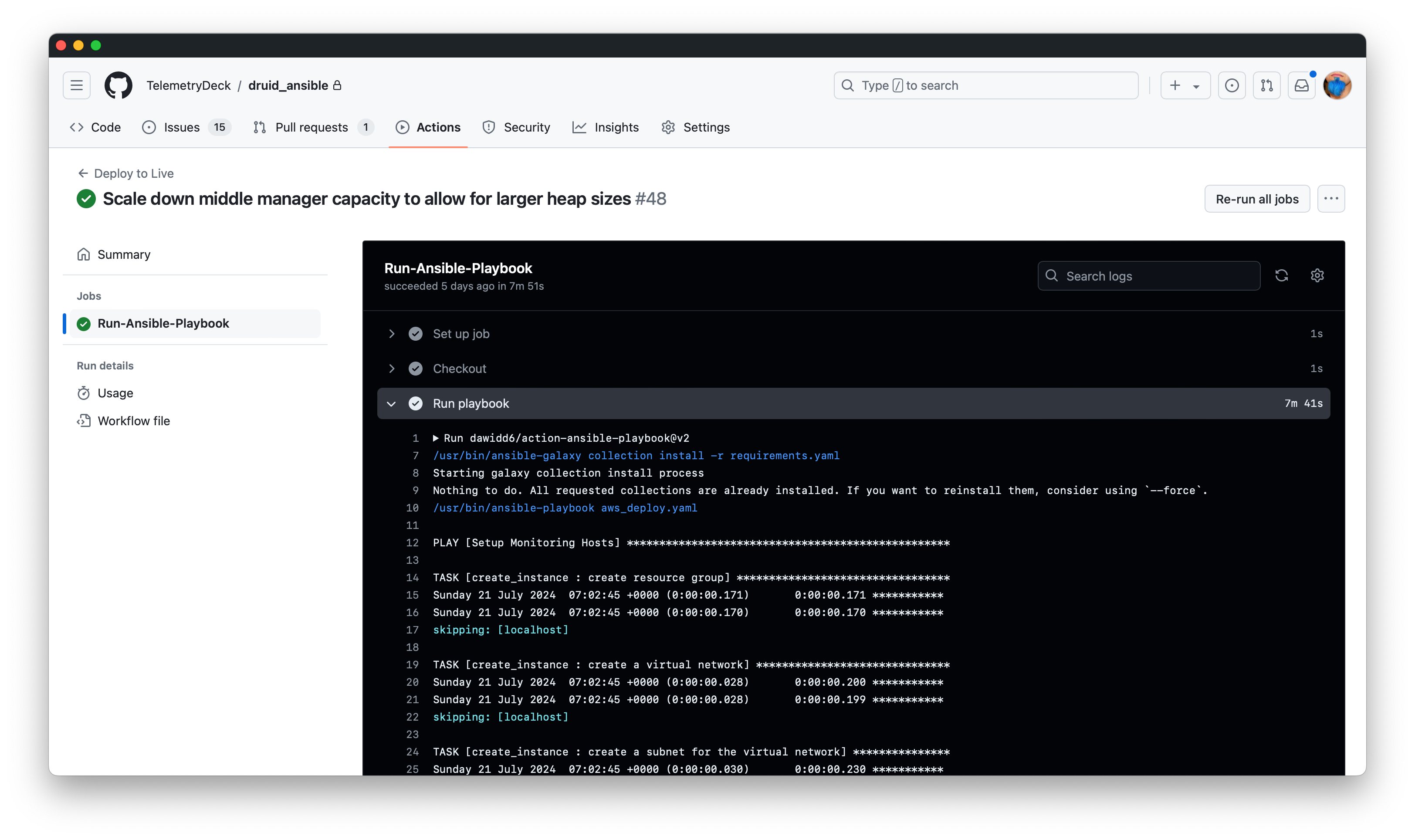
We're now using Ansible to instantiate any needed machines, and install everything they need to join the cluster automatically.
Ansible allows us to define the desired state of machines, services, installed software and so on, and ensures the servers match this state. This approach is cool, fun, repeatable, reliable and just as comfortable as Kubernetes.
Gotta stay compact
Back in ye olden days, you'd have to run a defragmentation program on your computer every now and then. It would clean up and reorder your files so that they could be read from disk more quickly.

Apache Druid servers have a very similar process called compaction, which orders data segments by date, app ID, test mode status, and various other properties. When a segment has been processed this way, queries on it run faster by a factor of up to 15x!
Sometime last year, we've discovered we couldn't run the compaction processes on our Kubernetes-based architecture any more, because it was one of the sources for RAM spikes that would take out half the cluster, so we had to turn it off and suffer the performance loss.
I'm super happy to say that compaction now runs flawlessly on our new architecture. As of now, about 3% of our segments are fully compacted, and performance should soar upwards as that percentage gets larger.
Thanks for being awesome!
In addition to Druid, our message queue has also been migrated to AWS, while our ingest and query APIs still operate on Azure within the Kubernetes cluster, at least for now. They like it there!
Testing these configurations and running deployments can be time-consuming, often involving waiting periods for provisioning and task execution. Despite these challenges, the new setup has significantly improved our system's performance and stability.
This migration has been a major step in optimizing TelemetryDeck's infrastructure. We're better positioned to handle our growing data needs and provide a more reliable service to our fantastic users. As we continue to refine our setup, we look forward to even greater efficiency and performance improvements.
Thanks so much for all your feedback, and your kind words. Stay tuned for more updates as we complete this migration and continue our work on making TelemetryDeck more and more awesome and privacy-friendly.